社内ナレッジ活用というと、すぐにRAG、ベクトルDB、埋め込み検索の話になりがちです。確かにRAGは有効な選択肢です。しかし実務では、AIが既存のGmail、OneDrive、SharePoint、Google Drive、GitHub、ファイルサーバー検索を高速に使うだけで価値が出る場面があります。
この記事の要点
- RAGは強力だが、構築、権限管理、鮮度管理、評価の運用が必要になる。
- 既存データソースには、すでに検索インデックスや権限管理がある場合が多い。
- AIを検索オペレーターとして使うだけで改善できる業務から始める選択肢がある。
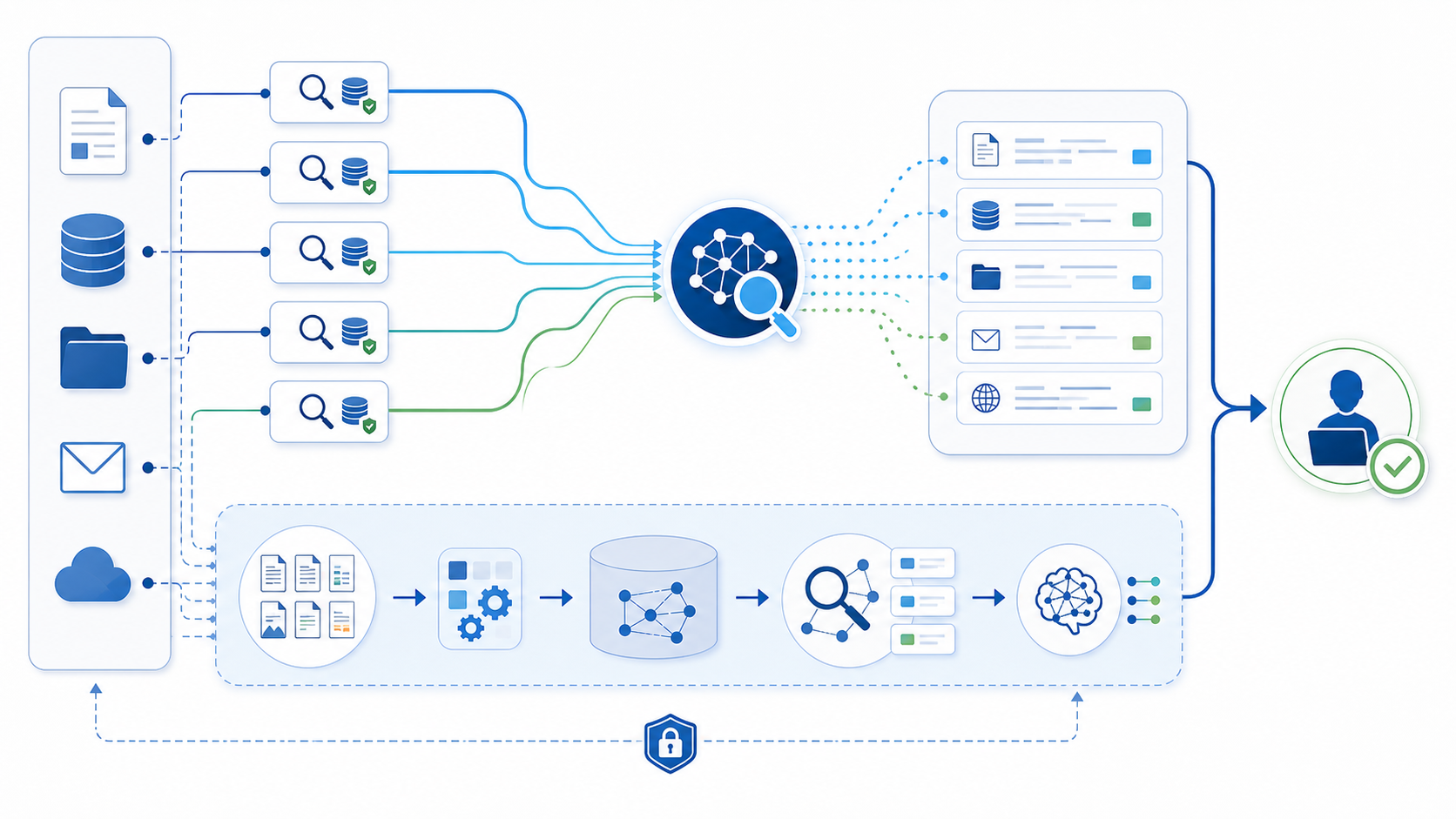
RAGは正解だが、最初の一手とは限らない
RAGは、社内文書を検索し、根拠を参照しながら回答する仕組みとして注目されています。ただし、RAG基盤を作るには、対象文書の収集、分割、ベクトル化、権限反映、鮮度管理、回答評価、ログ管理が必要です。小さな検索課題に対して、最初から大きな基盤を作ると、運用負担が先に来る場合があります。
社内にはすでに検索できる場所があります。メール、ファイルストレージ、チャット、GitHub、SaaS、ファイルサーバーには、検索インデックスやアクセス権限が備わっていることが多い。AIがそれらを使い、複数の検索語や言い換えを試し、結果を比較するだけでも、人間の検索時間を減らせます。
AIは人間より多くの検索語を試せる
人間の検索は、思いついた数語に依存します。ファイル名、担当者名、日付、略称、表記ゆれを外すと、情報が存在しても見つかりません。AIは、質問内容から関連語、言い換え、期間、固有名詞、英語表記、日本語表記を組み合わせ、短時間に複数パターンを試せます。
これは古いキーワード検索を軽視しない考え方です。キーワード検索は、権限管理や鮮度が既存システム側に残っているため、企業ITにとって扱いやすい場合があります。AIが検索結果を読み比べ、候補をまとめ、根拠リンクを提示するだけでも、社内ナレッジ活用は前進します。
先に見るべきは検索体験ではなく、データの置き場所
社内ナレッジ活用の難しさは、検索技術だけではありません。どの文書がどこにあるのか、誰が見られるのか、古い資料をどう扱うのか、回答の根拠をどう確認するのか。RAGを使う場合も、既存検索を使う場合も、この整理は避けられません。
だからこそ、いきなり全社RAGを作る前に、AIが既存検索を使う方式で業務ごとの価値を見極めることには意味があります。どのデータソースが重要か、どの検索語で見つからないか、どの権限が障害になるかが見えてから、RAG化する範囲を決めても遅くありません。
既存検索をAIで使う
まず小さく試しやすい。既存の権限と検索インデックスを活用できる。
RAG基盤を作る
横断検索や回答体験を統一しやすいが、文書管理と評価運用が必要。
併用する
重要文書はRAG、広範な探索は既存検索という分け方も現実的。
閉域AI・社内データ活用を相談する
閉域AI、社内データ活用、拠点間ネットワーク、音声・録音データ、クラウド接続など、AIを業務環境に組み込むためのインフラ構成についてご相談ください。
既存ネットワーク、PBX、データセンター、業務システムとの接続を前提に、実装しやすい構成を整理します。
要件を相談する